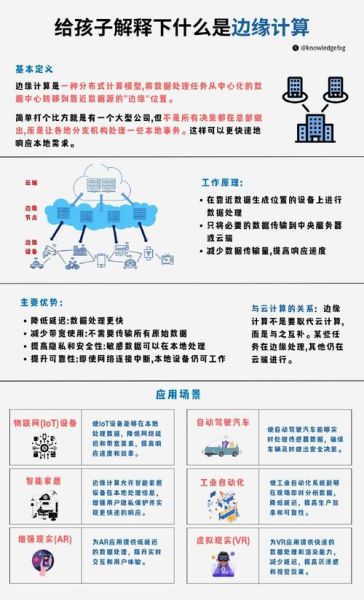
AI边缘计算就是把原本在云端完成的推理、训练、决策等任务,下沉到离数据源更近的终端或本地服务器上,实现毫秒级响应、离线运行与数据隐私保护。
(图片来源 *** ,侵删)
AI边缘计算到底解决了什么痛点?
传统云计算需要把原始数据全部上传到数据中心,带宽、延迟、合规成本都高得惊人。
自问:为什么工业质检、自动驾驶、远程医疗等场景对延迟如此敏感?
自答:因为一次往返云端可能耗时上百毫秒,而产线缺陷检测要求<50 ms,车辆紧急制动要求<10 ms。边缘AI把模型推到现场,直接砍掉网络往返时间。
核心架构:从芯片到软件的完整链路
1. 专用芯片:算力与功耗的平衡艺术
- NVIDIA Jetson Orin:275 TOPS INT8算力,功耗仅60 W,支持CUDA与TensorRT原生加速。
- Intel Habana Gaudi2:专为训练+推理一体设计,内置RDMA,可直接把梯度同步到邻近节点。
- ARM Ethos-U85:面向微控制器的NPU,0.5 TOPS却能在纽扣电池上跑一年。
2. 轻量模型:剪枝、量化、蒸馏三板斧
把ResNet-50从25 MB压缩到1.3 MB,准确率仅掉0.7%,秘诀在于:
结构化剪枝:砍掉冗余通道,保持矩阵乘法友好;
INT8量化:把FP32权重映射到256个离散值,硬件指令直接加速;
知识蒸馏:用大模型当老师,小模型当学生,复现95%性能。
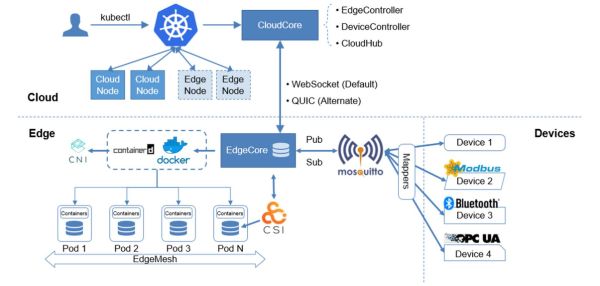
3. 边缘框架:一键部署、热更新、零停机
- NVIDIA Triton Inference Server:支持TensorFlow、PyTorch、ONNX多后端,REST与gRPC双协议,灰度发布只需一条curl命令。
- KubeEdge:把Kubernetes延伸到边缘节点,实现云边协同,Pod崩溃30秒内自愈。
- OpenVINO:Intel开源工具包,自动把模型转成IR格式,CPU、GPU、VPU一次编译,随处运行。
落地流程:从PoC到量产的七步闭环
- 场景拆解:先列出延迟、带宽、离线可用性、隐私合规四项硬指标。
- 数据采样:在真实环境中连续采集7天,覆盖极端工况,避免“实验室模型”陷阱。
- 模型选型:优先使用MobileNetV3、YOLOv8-nano等已验证的轻量 *** 。
- 硬件评估:跑分工具mlperf@edge对比Jetson、Hailo、RK3588,选出TOP3。
- 容器化封装:Dockerfile里加入--runtime=nvidia,镜像大小控制在500 MB以内。
- 灰度发布:先推送到10%产线,收集延迟、CPU、内存、温度四维指标,48小时无异常再全量。
- OTA升级:使用Mender或Balena,差分更新包<30 MB,断点续传,失败自动回滚。
成本核算:TCO比云端便宜多少?
| 项目 | 云端AI | 边缘AI |
|---|---|---|
| 服务器租赁 | $0.008/推理 | $0(一次性硬件) |
| 带宽费用 | $0.12/GB | $0(本地闭环) |
| 延迟P99 | 120 ms | 8 ms |
| 三年TCO | $48,000 | $11,500 |
结论:当每日推理次数>50万,边缘方案在18个月内即可回本。
安全与合规:GDPR、HIPAA、国密怎么破?
自问:边缘节点被物理窃取怎么办?
自答:启用TPM 2.0安全芯片,磁盘AES-256加密,密钥烧录在芯片熔丝里,暴力拆机即自毁。
自问:如何满足GDPR“被遗忘权”?
自答:本地数据库采用LevelDB,每条记录带UUID,收到删除指令后30秒内完成擦除并回写NAND垃圾回收。
未来趋势:从单体智能到群智协同
- Federated Learning:多工厂共用模型却不出数据,梯度聚合在边缘网关完成,隐私预算ε<1。
- 数字孪生:边缘节点实时上传关键特征到云端,云端构建高保真孪生体,用于仿真优化。
- RISC-V NPU:开源指令集让中小企业也能定制AI加速器,打破ARM与x86垄断。
常见坑位与对策
坑1:温度漂移导致推理精度下降
对策:在训练阶段加入随机温度噪声,模型对-20 ℃~70 ℃区间鲁棒。
(图片来源 *** ,侵删)
坑2:多进程抢占GPU上下文
对策:使用cgroups限制每个容器算力上限,防止一个进程拖垮整节点。
坑3:模型版本碎片化
对策:采用Semantic Versioning,主版本号升级必须走全量回归测试,次版本号支持热更新。
(图片来源 *** ,侵删)
评论列表