“历史遗留项目”四个字往往让技术团队、产品、运营同时皱眉:代码看不懂、文档缺失、需求反复、上线风险高。如何高效处理?答案就在“先分类、后拆解、再重构、终沉淀”四步闭环。
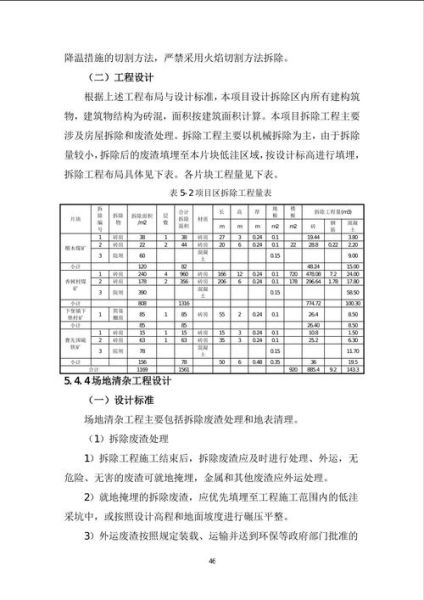
(图片来源 *** ,侵删)
什么是历史遗留项目?
它通常具备以下特征:
- 技术栈陈旧:仍在跑 JDK 1.6、jQuery 1.x、Python 2.7。
- 文档缺失:README 只有一句话“请直接问老王”。
- 人员流失:原作者离职,继任者又换了两拨。
- 业务耦合:一个下单接口同时管库存、优惠券、积分、日志。
只要满足其中两条,就可以判定为“历史遗留”。
为什么必须正视而不是绕过?
常见逃避理由有三:
- “先跑起来再说,重构太花时间。”——结果越拖越慢,Bug 翻倍。
- “业务方不同意停新需求。”——可用灰度+并行版本解决。
- “团队不会旧技术。”——正好借机会做知识交接+培训。
不处理的代价:线上事故、客户流失、 *** 困难、技术债利息滚雪球。
四步闭环:从混乱到可控
之一步:全景盘点,建立“遗产地图”
用两周时间完成:

(图片来源 *** ,侵删)
- 代码扫描:SonarQube +依赖树,列出漏洞、重复、复杂度 Top。
- 接口梳理:Swagger/OpenAPI 反向生成,缺失的手动补。
- 数据盘点:表数量、核心字段、无主键表、慢 SQL。
- 人员访谈:找到最后三位维护者,录音+文字沉淀。
产出物:一份“一页纸遗产地图”,贴在 Wiki 首页,每周更新。
第二步:风险分级,先止血后动刀
把模块按业务影响×技术风险画四象限:
| 高业务影响 | 低业务影响 | |
|---|---|---|
| 高技术风险 | 之一优先级:支付、登录 | 第二优先级:报表导出 |
| 低技术风险 | 第三优先级:活动页 | 第四优先级:内部工具 |
止血动作示例:
- 支付模块:加熔断+限流,防止雪崩。
- 登录模块:引入双写兼容,新旧 Token 并存。
第三步:渐进重构,而非重写
重写是“大爆炸”,重构是“换轮胎不停车”。
策略一:绞杀者模式

(图片来源 *** ,侵删)
- 新功能全部在新服务实现。
- 旧接口做 *** 转发,逐步迁移流量。
- 当旧接口流量<5%,一次性下线。
策略二:分支抽象
- 把公共逻辑抽到共享库。
- 用特性开关控制新旧实现切换。
- 每完成一个模块,跑回归+压测,确保无回退。
第四步:知识沉淀,防止再次“遗留”
把重构过程本身变成资产:
- 文档即代码:README、ADR(架构决策记录)与代码同仓。
- 自动化测试:单元、接口、端到端覆盖率≥80%。
- 监控三板斧:日志、指标、链路追踪全部接入。
- 新人 Onboarding 清单:30 分钟能跑通本地环境。
每季度安排一次“遗产回顾会”,更新地图、复盘教训。
常见疑问快问快答
Q1:老板不给排期怎么办?
A:把技术债折算成事故成本,用数据说话。例如“支付接口 500 错误率 0.5%,每月流失订单 300 单,按客单价 200 元算,月损失 6 万”。
Q2:旧框架找不到人维护?
A:三步走:
- 内部挑两人做“框架守护人”,给晋升通道。
- 外部请顾问做2 周封闭式培训。
- 把关键逻辑用领域语言写成 DSL,降低理解门槛。
Q3:测试环境数据太脏?
A:用数据子集+脱敏方案:
- 生产库按 1% 采样,敏感字段 Hash。
- 写 Docker Compose 一键拉起,保证每人环境一致。
工具箱推荐
- 代码扫描:SonarQube、Semgrep
- 依赖分析:Snyk、OWASP Dependency-Track
- 接口文档:Swagger-Codegen、SpringDoc
- 数据库迁移:Flyway、Liquibase
- 特性开关:Unleash、LaunchDarkly
- 灰度发布:Argo Rollouts、Spinnaker
真实案例:电商订单系统 8 周重生记
背景:十年老系统,PHP 5.3 + MyISAM,日均 2 万单。
- 第 1-2 周:遗产地图出炉,发现 47 个慢 SQL,更大表 2.3 亿行。
- 第 3-4 周:把下单接口拆成订单、库存、优惠券三个服务,用 Kafka 做最终一致。
- 第 5-6 周:数据迁移,使用双写+校验,回滚窗口 10 分钟。
- 第 7-8 周:灰度切流,从 1% 到 100% 用 5 天完成,零事故。
结果:接口 P99 从 2.1s 降到 280ms,服务器从 18 台缩到 6 台。
历史遗留项目不是“烫手山芋”,而是被低估的金矿。只要用对 *** ,它就能成为团队技术跃迁的跳板。
评论列表