历史时空大全到底是什么?
很多人之一次听到“历史时空大全”时,会把它当成一本厚重的纸质年表,其实它是一套跨学科、跨媒介的时空数据库,把政治、经济、文化、科技、地理等多维信息整合到同一条时间轴上。换句话说,它像一台“时空显微镜”,让你随时放大或缩小,观察某个朝代、某一年,甚至某一天的世界在发生什么。
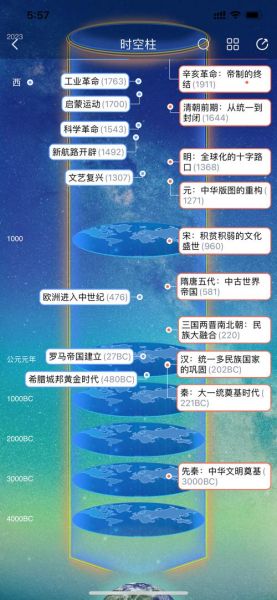
为什么需要历史时空大全?
1. 解决“时间错位”带来的误解
你是否曾把李白与苏轼放在同一饭局?历史时空大全通过可视化时间轴,自动标注人物生卒年,避免“关公战秦琼”的尴尬。
2. 打通“空间孤岛”的信息壁垒
同一时期,长安的坊市制度与巴格达的智慧宫如何互动?系统把地理坐标、贸易路线、人口流动叠加在地图上,让“世界史”不再是各国史的简单拼贴。
3. 为研究提供“可验证”的数据源
每条记录都附带原始文献编号、考古报告链接、碳十四测年区间,研究者可以一键回溯证据链,减少“拍脑袋”式结论。
如何正确使用历史时空大全?
之一步:锁定“时空锚点”
先问自己:我想解决的核心问题是什么? 例如:
- “安史之乱对丝绸之路贸易量的影响”——锚点是755-763年、长安至撒马尔罕的贸易节点。
- “黑死病如何改变欧洲劳动力价格”——锚点是1347-1353年、地中海港口城市。
第二步:选择“维度切片”
系统提供政治、经济、文化、气候、疾病、技术六大维度。 举例:
- 勾选“气候”维度,发现1320年代北半球小冰期导致蒙古草原减产,间接推动帖木儿东征。
- 叠加“技术”维度,看到同期 *** 随蒙古西传,改变了欧洲城堡建筑比例。

第三步:验证“数据血缘”
每条记录右侧都有“证据链”按钮,点击后会出现:
- 原始档案:如《旧唐书·食货志》卷四三。
- 现代研究:如Twitchett《剑桥中国隋唐史》页码。
- 考古佐证:如撒马尔罕古城出土的粟特文账本残片。
常见误区与避坑指南
误区一:把“时空大全”当“答案大全”
系统不会告诉你“为什么罗马会衰亡”,它只提供410年罗马城被攻陷时的粮食价格、军队人数、匈人迁徙路线。真正的因果分析,仍需研究者自己构建。
误区二:忽略“数据颗粒度”差异
中国汉代县级人口记录可精确到千位,而同时期日耳曼部落人口只能估算到万位。强行对比会导致“假精确”,需在注释中说明误差范围。
误区三:迷信“可视化”而丢弃文本
地图上的箭头再漂亮,也替代不了《高卢战记》里凯撒对赫尔维蒂人迁徙动机的描述。时空大全是放大镜,不是替身。
进阶技巧:用API打造个人研究助手
历史时空大全开放RESTful API,三行Python代码即可批量抓取数据:
import requests
url = "https://api.historicalatlas.org/event"
params = {"year": 1368, "region": "Central_Asia", "dimension": "trade"}
data = requests.get(url, params=params).json()
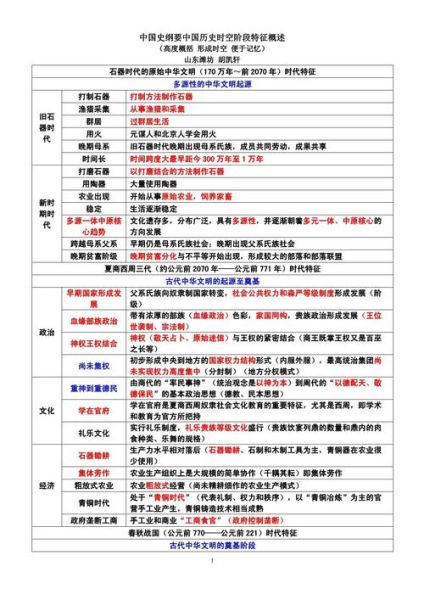
未来展望:从“大全”到“全息”
下一代系统计划引入AI语义网,自动识别文本中的隐性关联。例如:当你输入“郑和下西洋”,系统会提示“同期马穆鲁克苏丹国对红海港口的关税政策”,并给出原始 *** 语档案的英译链接。研究者不再“检索”,而是“对话”。
自问自答:三个最常被私信的问题
Q1:免费版和付费版差距大吗?
免费版可查看公元前后各500年的公开数据;付费版解锁中世纪欧洲修道院账簿、敦煌吐鲁番文书等高分辨率扫描件,并支持API批量下载。
Q2:如何处理“互相矛盾”的史料?
系统会在冲突记录旁标注“争议标识”,并列出不同学派的观点。例如关于“怛罗斯之战唐军人数”,《通典》记2万, *** 史家记10万,你可以下载双方引用的原始段落,自行判断。
Q3:非历史专业能用吗?
完全可以。高中教师用它做“动态年表”课件,游戏策划用它考据《刺客信条》背景,小说作者用它查“1380年莫斯科的市集税是多少”。只要会拖拽时间轴,就能上手。
评论列表